Modern Data Warehouse Architecture
In today’s data-driven world, organisations need to leverage their data effectively to gain insights, drive decision-making, and maintain a competitive edge. A modern data warehouse is a critical component in this process, enabling the efficient collection, storage, and analysis of vast amounts of data from various sources. This blog delves into what a modern data warehouse is, its benefits, the differences between traditional and modern architectures, core components, architectural strategies, future trends, and essential tools for building a modern data warehouse solution.
It serves as a guide for organisations looking to build or upgrade their data warehousing solutions in the modern digital landscape.
What is a Modern Data Warehouse?
A modern data warehouse is an advanced data storage and management solution designed to handle the massive volumes, variety, and velocity of data generated by today’s digital ecosystem. Unlike traditional data warehouses, which were primarily built to manage structured data from transactional systems, modern data warehouses are equipped to integrate, store, and analyze both structured and unstructured data from multiple sources, including cloud platforms, IoT devices, social media, and big data environments.
Modern data warehouses use cloud-native technologies, enabling scalable, flexible, and cost-effective data management solutions. They often incorporate real-time data processing, advanced analytics, and machine learning capabilities to deliver actionable insights quickly and efficiently.
Why is a Modern Data Warehouse Important?

Lower upfront costs
Even as hardware costs continue to decrease, it’s still expensive to purchase your own equipment.
If the upfront costs weren’t enough, on-premises equipment also requires regular maintenance, increases power bills and depreciates over time to the point where it needs to be replaced.
By contrast, modern data warehouses’ cloud infrastructure takes advantage of economies of scale in computing. In other words, service providers dedicated to providing cloud resources have already invested millions of dollars in providing massive amounts of computing power — and the ongoing maintenance and upgrades that follow.
As a result, renting a relatively tiny fraction of cloud resources is much less expensive than purchasing and maintaining the equivalent on-premises.
Less maintenance
Using cloud infrastructure eliminates the need for ongoing maintenance. This not only saves money and time but also eliminates potential errors and downtime due to scheduled updates, equipment replacement, security breaches and so on.
While cloud providers aren’t necessarily immune to these issues, they can usually guarantee near-constant availability and strong security while keeping hardware upgrades and replacements in the background.
Faster speeds
Modern, cloud-based warehousing is typically much faster than its traditional, on-premises counterpart.
While part of this is due to more computing power and processing resources available, the use of ELT over ETL is another major contributor. Here, ELT can better leverage data replication tools to load vast amounts of data at once and then transform as needed rather than the other way around.
More flexibility
Since cloud infrastructure deploys virtual instances on top of physical, distributed hardware, providers can easily switch between various formats, data types and warehouse architectures — and even logically combine them. By contrast, traditional data warehouses that use relational databases are often limited to data of a similar type or format.
Easier to scale
Cloud flexibility is also synonymous with scalability. Again, since space is allocated virtually, it’s possible to allocate more or less resources at a moment’s notice. This makes it easier to take on larger workloads and import more data as you find new ways to utilise your data warehouse.
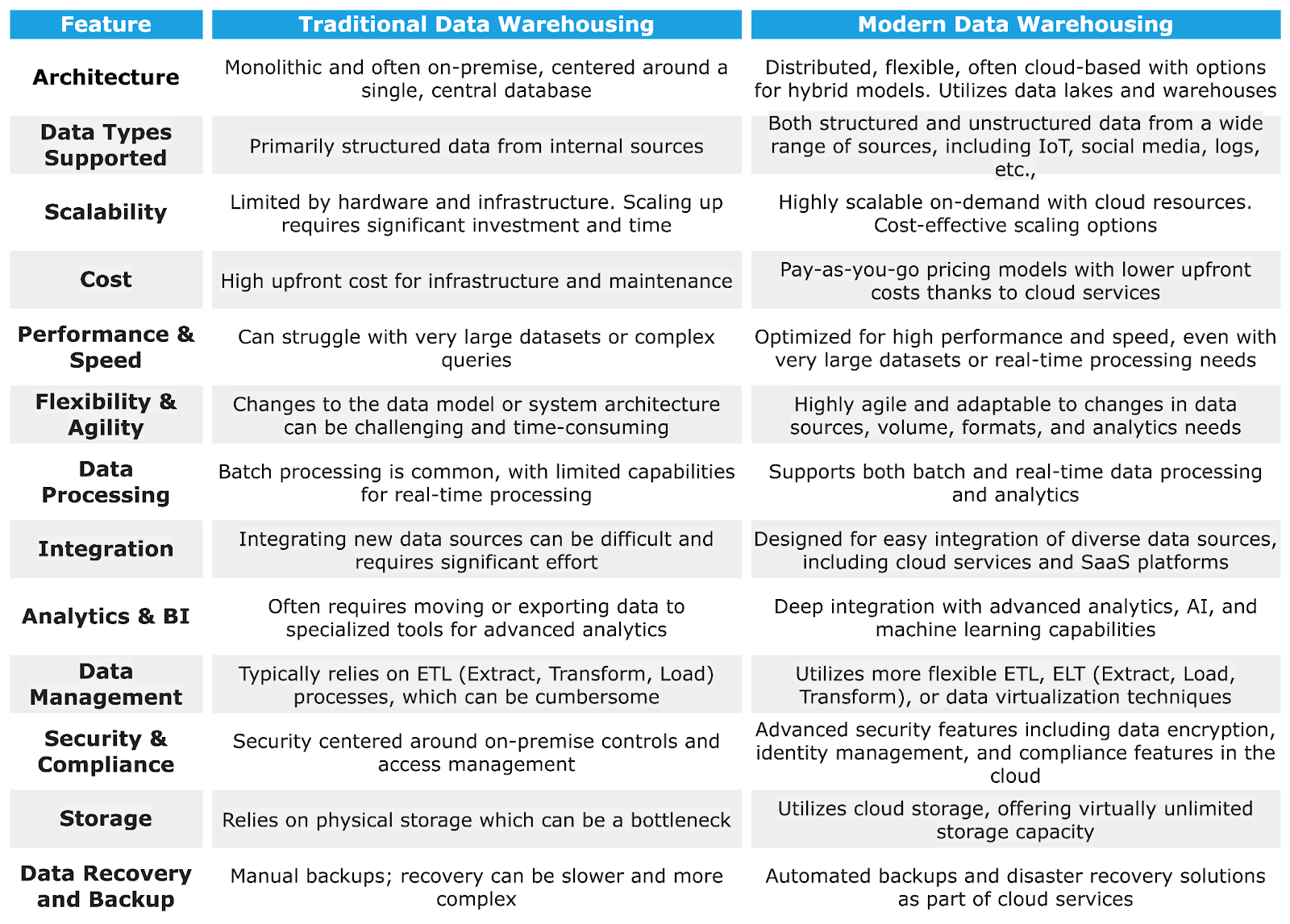
Traditional vs. Modern Data Warehouse
Core Components of a Modern Data Warehouse
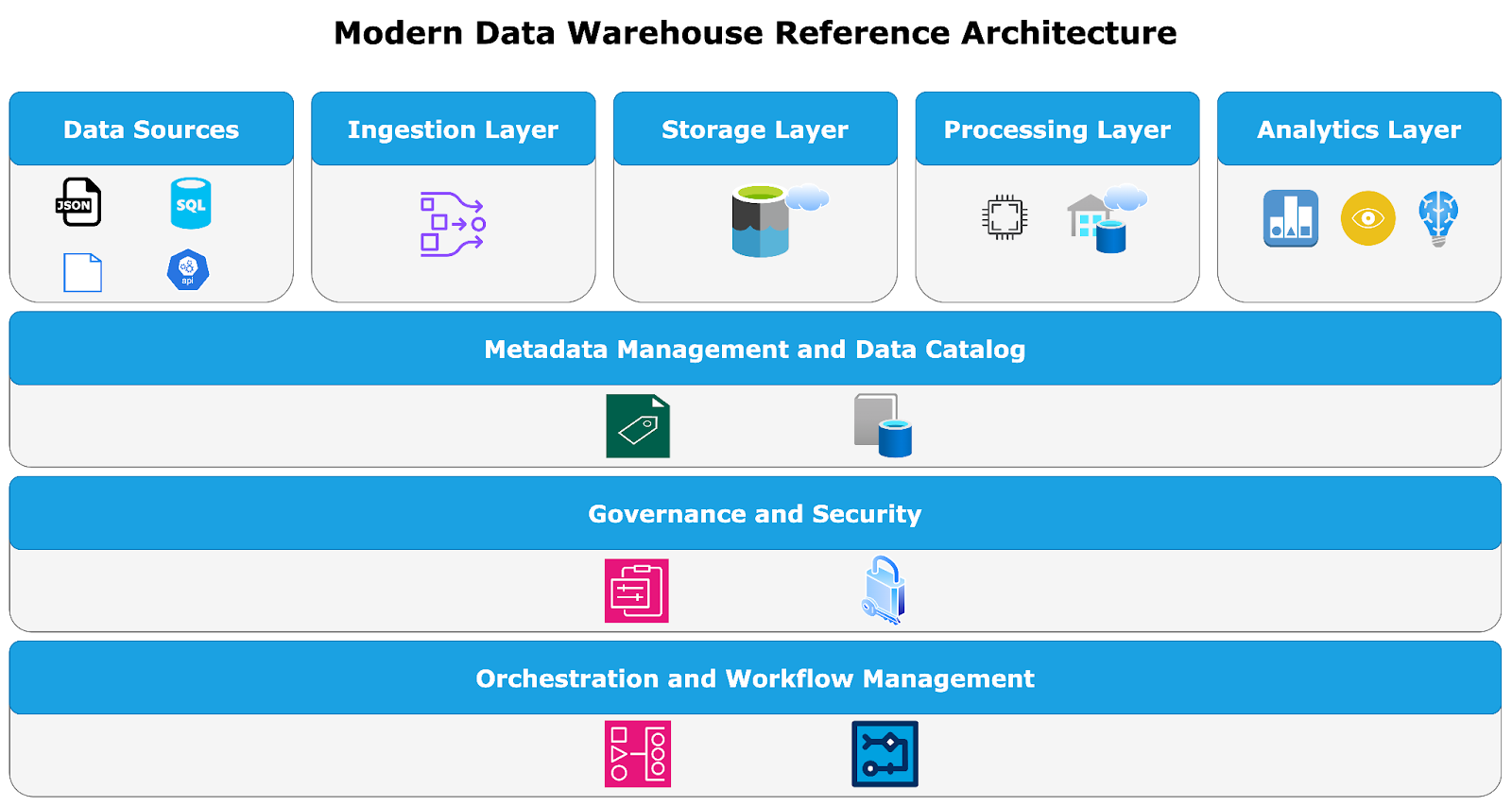
A modern data warehouse is composed of several key components that work together to provide a comprehensive data management and analytics solution:
Data Sources
The origin points of data, including transactional databases, social media, IoT devices, external APIs, and big data environments.
Ingestion Layer
Responsible for collecting and loading data into the warehouse, typically using ETL or ELT processes. This layer often includes tools for real-time data streaming.
Storage Layer
Where data is stored, often in a cloud-based, distributed storage system that can scale based on demand. Data lakes are commonly used to store raw data in its native format.
Processing Layer
The component that processes and transforms raw data into structured formats suitable for analysis. This layer may include big data processing frameworks like Apache Spark or Hadoop.
Analytics Layer
The interface through which users can interact with and analyze the data. This layer includes BI tools, SQL interfaces, and machine learning platforms.
Metadata Management and Data Catalog
Metadata helps in data discovery, lineage tracking, and ensuring data quality, which are crucial for effective analytics. A data catalogue can help users discover and understand the data available within the warehouse, making self-service analytics more effective.
Governance and Security
Ensures that data is managed according to regulatory requirements and organisational policies. This component includes tools for data quality management, access control, and auditing.
Orchestration and Workflow Management
Manages the flow of data across the different layers, ensuring data is processed and available when needed. This may involve tools like Apache Airflow or Azure Data Factory.
Architectural Strategies for a Modern Data Warehouse
To build an effective modern data warehouse, organisations should consider several key architectural strategies:
Cloud-Native Architecture
Leverage cloud platforms to achieve scalability, flexibility, and cost-efficiency. Cloud-native data warehouses such as Snowflake, Amazon Redshift, or Google BigQuery are popular choices.
Data Lake Integration
Use data lakes to store raw, unstructured data, which can then be processed and transformed as needed. This approach allows for a “store now, analyse later” methodology.
Data Lakehouse Architecture
The data lakehouse architecture combines the benefits of a data lake and a data warehouse. This architecture allows for both structured and unstructured data processing and provides a unified platform for data storage, management, and analytics.
Event-Driven Architecture
Event-driven architectures in modern data warehouses enables real-time processing and analytics by reacting to events as they occur, which is crucial for use cases like fraud detection or live customer insights.
Hybrid Architecture
Combine on-premise and cloud resources to balance data governance, performance, and cost considerations. This is particularly useful for organisations with existing on-premise investments.
Microservices and Containerisation
Use microservices and containers to modularise the data warehouse architecture, enabling easier scaling and deployment of individual components.
Serverless Computing
Take advantage of serverless technologies to automatically scale compute resources based on demand, reducing the need for manual infrastructure management.
Real-time Processing
Implement streaming data pipelines and real-time analytics to process and analyse data as it arrives, providing immediate insights.
Future Trends in Modern Data Warehousing
As technology continues to evolve, modern data warehouses will likely see several trends shaping their development:
AI and Machine Learning Integration
Greater integration of AI and machine learning capabilities within the data warehouse to automate data processing and predictive analytics.
Edge Computing
As IoT devices proliferate, data processing at the edge (closer to the data source) will become more prevalent, reducing latency and bandwidth requirements.
Data Mesh Architecture
A shift towards decentralised data architecture, where data ownership is distributed across domain-oriented teams, allowing for more agile and scalable data management.
Data Fabric
There is an emerging trend of data fabric architecture, which aims to provide a unified data management framework across distributed environments. Data fabric helps in seamlessly integrating, managing, and securing data across hybrid and multi-cloud environments.
Increased Automation
Automation of data ingestion, transformation, and analysis processes, reducing the need for manual intervention and speeding up data workflows.
Enhanced Data Governance
With growing data privacy concerns, data governance frameworks will become more robust, ensuring that data is handled in compliance with regulations like GDPR and CCPA.
Medallion Architecture
In a modern data warehouse, the Medallion Architecture complements other architectural strategies like Data Vault or data lakehouse by providing a clear framework for data organisation and processing. It is a layered approach to organizing data in a modern data warehouse and to improve data quality and enable efficient data processing by structuring data in different “tiers” based on its refinement level.
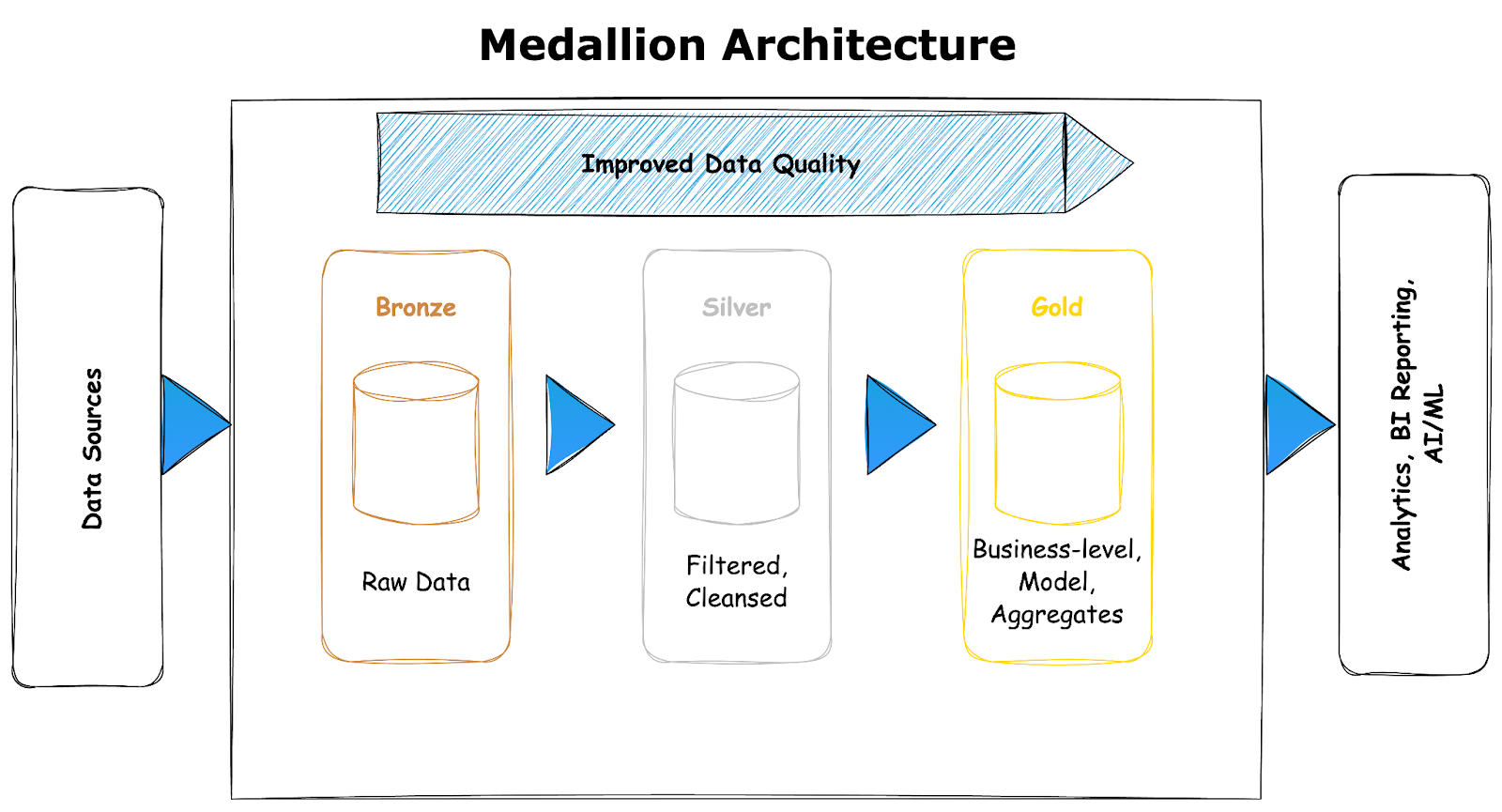
Layers of Medallion Architecture
- Bronze Layer (Raw Data): This is the ingestion layer where raw, unprocessed data from various sources is stored. The focus here is on capturing data in its native format with minimal transformation. It serves as the “single source of truth” for all subsequent layers.
- Silver Layer (Cleaned and Enriched Data): Data in the Silver Layer is cleaned, transformed, and enriched to make it more usable. This layer typically involves applying basic transformations like deduplication, data cleansing, and joining datasets. The Silver Layer is where the data starts to become more analytics-ready.
- Gold Layer (Aggregated and Curated Data): The Gold Layer contains highly curated, aggregated, and business-friendly data that is ready for reporting and analysis. This layer is often used for creating dashboards, business intelligence reports, and feeding machine learning models.
Benefits Medallion Architecture
- Improved Data Quality: By processing and refining data in stages, the Medallion Architecture ensures that only high-quality, curated data reaches the end users, reducing errors and improving decision-making.
- Optimised Data Processing: The layered approach allows for efficient data processing, as each layer builds upon the previous one, enabling incremental processing and reducing the need for reprocessing raw data.
- Scalability: The architecture is highly scalable, accommodating growing data volumes and evolving business requirements. Each layer can be scaled independently, allowing for flexibility in managing resources.
Data Vault Modeling Framework
In a modern data warehouse, Data Vault modeling provides a robust foundation for managing large volumes of diverse data. It is a data modelling methodology designed for building scalable and flexible data warehouses. It was developed to address some of the limitations of traditional data modelling techniques like star schema and snowflake schema, particularly in environments where data integration and change management are complex.
Key Concepts of Data Vault
- Hubs: Represent core business entities (e.g., customers, products). Each hub contains a unique list of business keys and serves as the central point of integration.
- Links: Capture the relationships between hubs. For example, a link might represent the relationship between customers and their orders.
- Satellites: Store descriptive attributes of the hubs and links, such as customer names, addresses, or order details. Satellites allow for tracking historical changes without affecting the core structure of the data warehouse.
Benefits of Data Vault
- Scalability: Data Vault’s modular approach allows for easy expansion as new data sources or business requirements emerge.
- Flexibility: The model accommodates changes in the business environment, such as new attributes or evolving relationships, without significant rework.
- Audibility: By design, Data Vault provides a complete audit trail of all data transformations and historical changes, ensuring data integrity and compliance with regulatory requirements.
Resources and Tools for Building a Modern Data Warehouse Solution
Building a modern data warehouse requires a combination of tools and platforms that cater to different components of the architecture:
Cloud Data Warehouses
Amazon Redshift, Google BigQuery, Snowflake, Microsoft Azure Synapse Analytics.
Data Integration Tools
Apache NiFi, Talend, Informatica, Fivetran, Stitch.
Big Data Processing Frameworks
Apache Spark, Apache Hadoop, Databricks.
BI and Analytics Tools
Tableau, Power BI, Looker, Qlik, Google Data Studio.
Orchestration Tools
Apache Airflow, Azure Data Factory, AWS Step Functions.
Data Governance Tools
Collibra, Alation, Informatica Data Governance, Apache Atlas.
Real-Time Data Streaming
Apache Kafka, Amazon Kinesis, Google Cloud Pub/Sub, Apache Pulsar.
By leveraging these tools and adhering to the architectural strategies discussed, organisations can build a modern data warehouse that meets their current and future data needs.
Conclusion
The shift from traditional to modern data warehouse architecture represents a significant evolution in how organisations manage and analyse their data. With the ability to handle diverse data types, scale on demand, and integrate advanced analytics, modern data warehouses are indispensable for organisations seeking to thrive in the digital age. As technology continues to advance, staying ahead of trends and adopting the right tools will ensure that your data warehouse remains a powerful asset in your business strategy.
Related articles