All data in the platform is treated as events. This provides high throughput, low latency, and easy scalability. You get an up2date picture of your critical business data at any time.
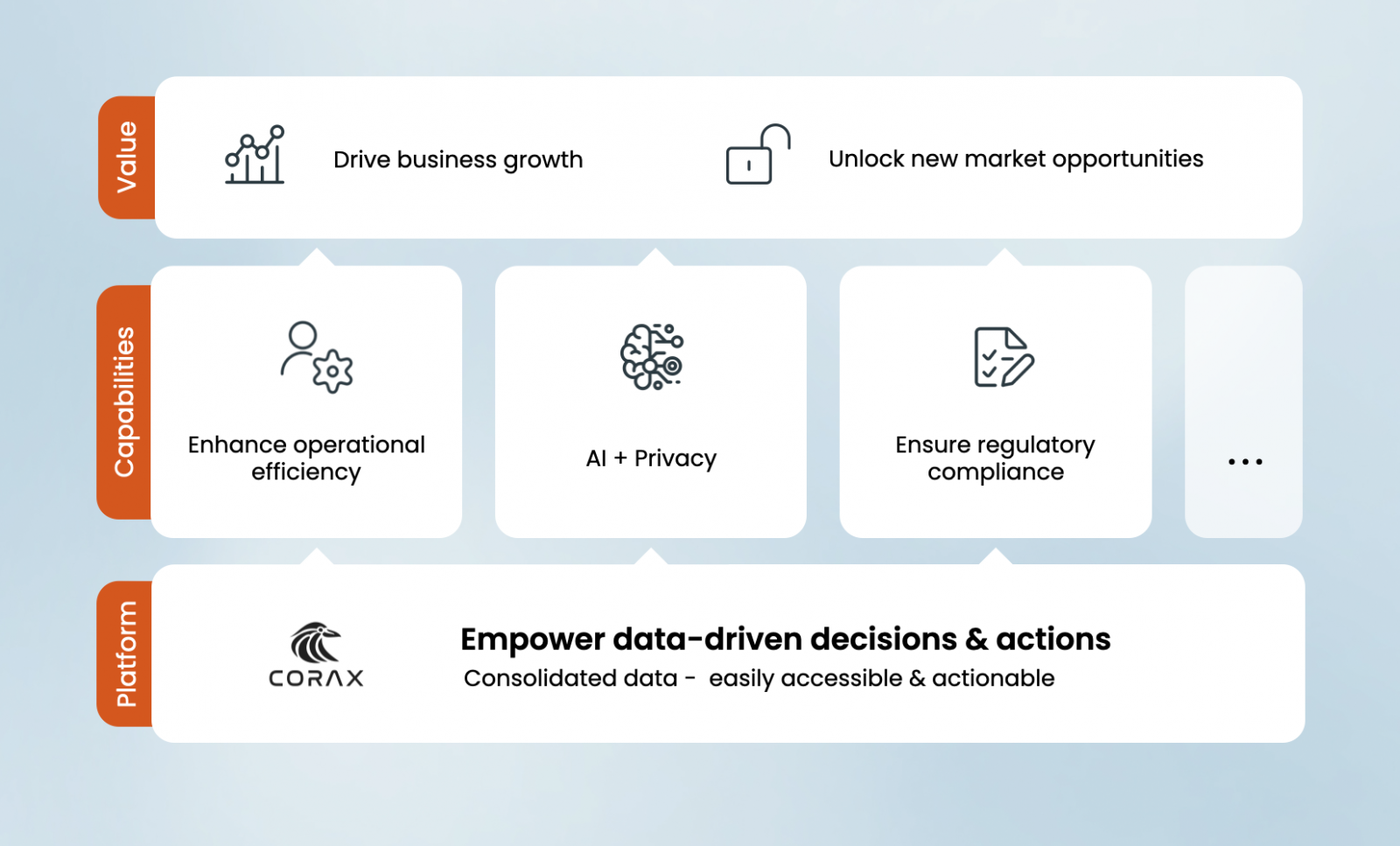
A well-managed data platform empowers you to make data-driven decisions and act proactively in real-time, thereby driving business growth and unlocking new business opportunities.
Trifork's data platform, Corax data, is based on a future-proof flexible architecture.
A well-managed data platform empowers you to make data-driven decisions and act proactively in real-time, thereby driving business growth and unlocking new business opportunities.
Trifork's data platform, Corax data, is based on a future-proof flexible architecture.
We see an increasing need for cross-team collaboration on data products and creating data insights across data sources / business domains – to support business goals with both analytics and customer facing applications.
All fortune 500 companies either have a data platform or will have one soon.
Corax Data is an advanced Data Platform that fosters digital transformations and empowers data-driven decisions and actions. Our flexible architecture can adapt to future technological developments.
We empower competitiveness through digitalization, consolidation of data enabling new insights, and the ability to build applications that support business goals.

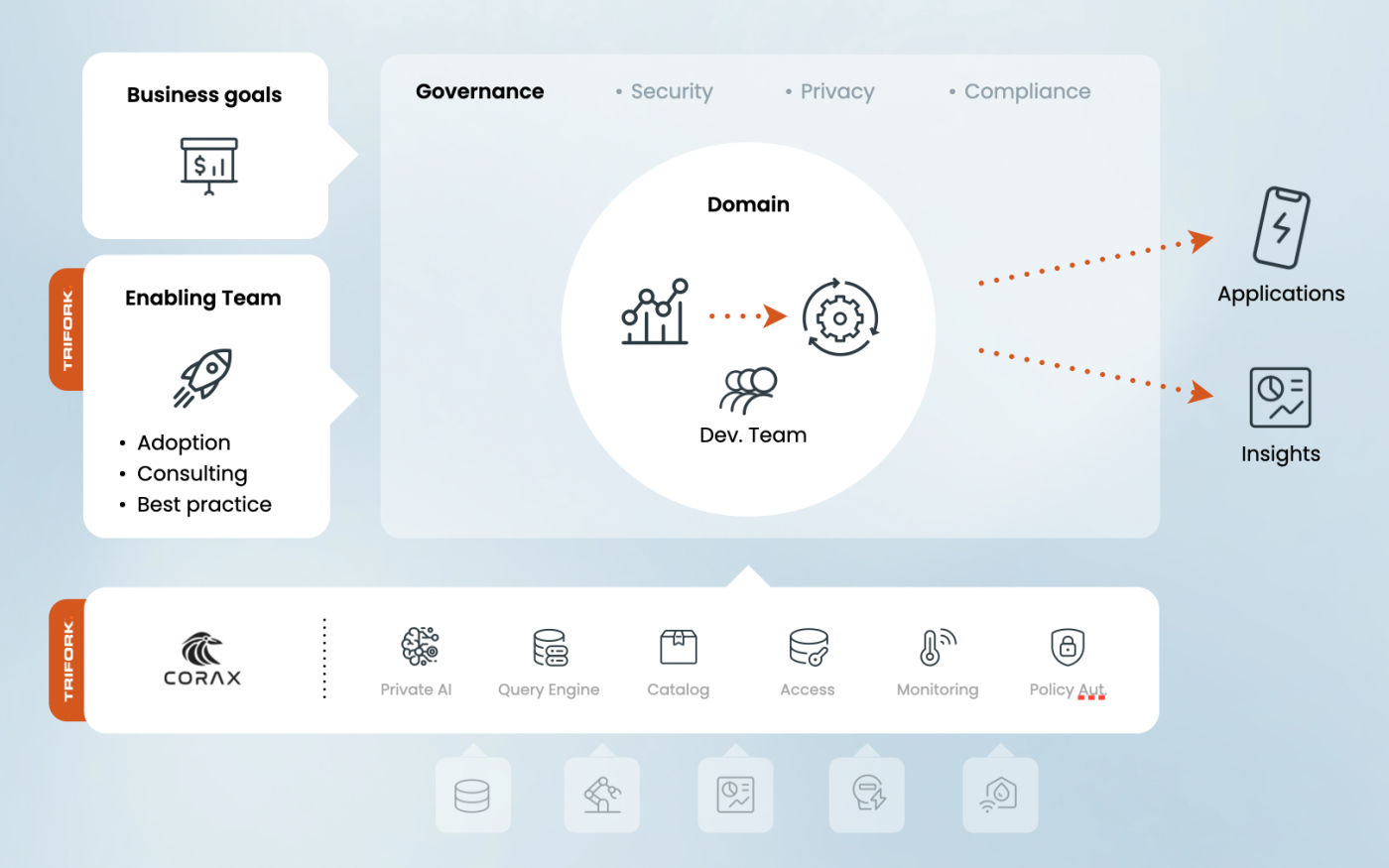
Corax data not only consolidates all your data from disparate sources, allowing for vital business insights, it also empowers your own developers to build applications that meet your business goals.
Our Enabling Team helps your developers with best practice and gives them an efficiency boost.

Disclaimer: This is not a 3rd party assessment, rather our own perception of the competitive situation

Corax data is event-driven and can grow with your business. It can handle all types of logs, API connections, data streams, and all standard document formats. Support for voice and pictures are on the product roadmap.
Corax data is event-driven and can grow with your business. It can handle all types of logs, API connections, data streams, and all standard document formats. Support for voice and pictures are on the product roadmap.

All data in the platform is treated as events. This provides high throughput, low latency, and easy scalability. You get an up2date picture of your critical business data at any time.

Advanced Multi-tenancy storage with configurable ILM policies. GDPR-compliant storage and admin tools. Dynamic mapping allows for data structures to develop over time. Proven scalability from Gb to Pb storage size.

Real-time processing, reporting, and alerting. Combine, enrich, aggregate, flat map, and mapReduce on your event stream. The platform provides a complete toolbox to manipulate data before storing it. A state store – Build up a state of an Entity over time – no need to save all the data used to calculate it.

The generic query engine allows you to add new data sources and ingest them into your existing application stack. This extends the lifetime and maintenance costs for your applications. The platform can also be used as a data gateway that can bridge across legacy systems or systems from acquired/merged companies. It also features dashboards with real-time visualization or real-time ingest to third-party systems.
Trifork can offer the platform as a developer license or a managed service with 24/7 operation. Read about the platform here
Trifork can offer the platform as a developer license or a managed service with 24/7 operation. Read about the platform here

GitOps deployment of the platform and your applications into the your preferred runtime environment. Platforms can be deployed on Kubernetes platform (on-prem or Cloud-based) and directly on infrastructure via containers.

Log framework for applications. Centralized log and metrics collection. Dashboards and Alerts based on metrics

The platform is built with best-practice security with Secure secret storage, Full encryption to all networks for secure communication, and encrypted storage. Audit framework for all platform operations.
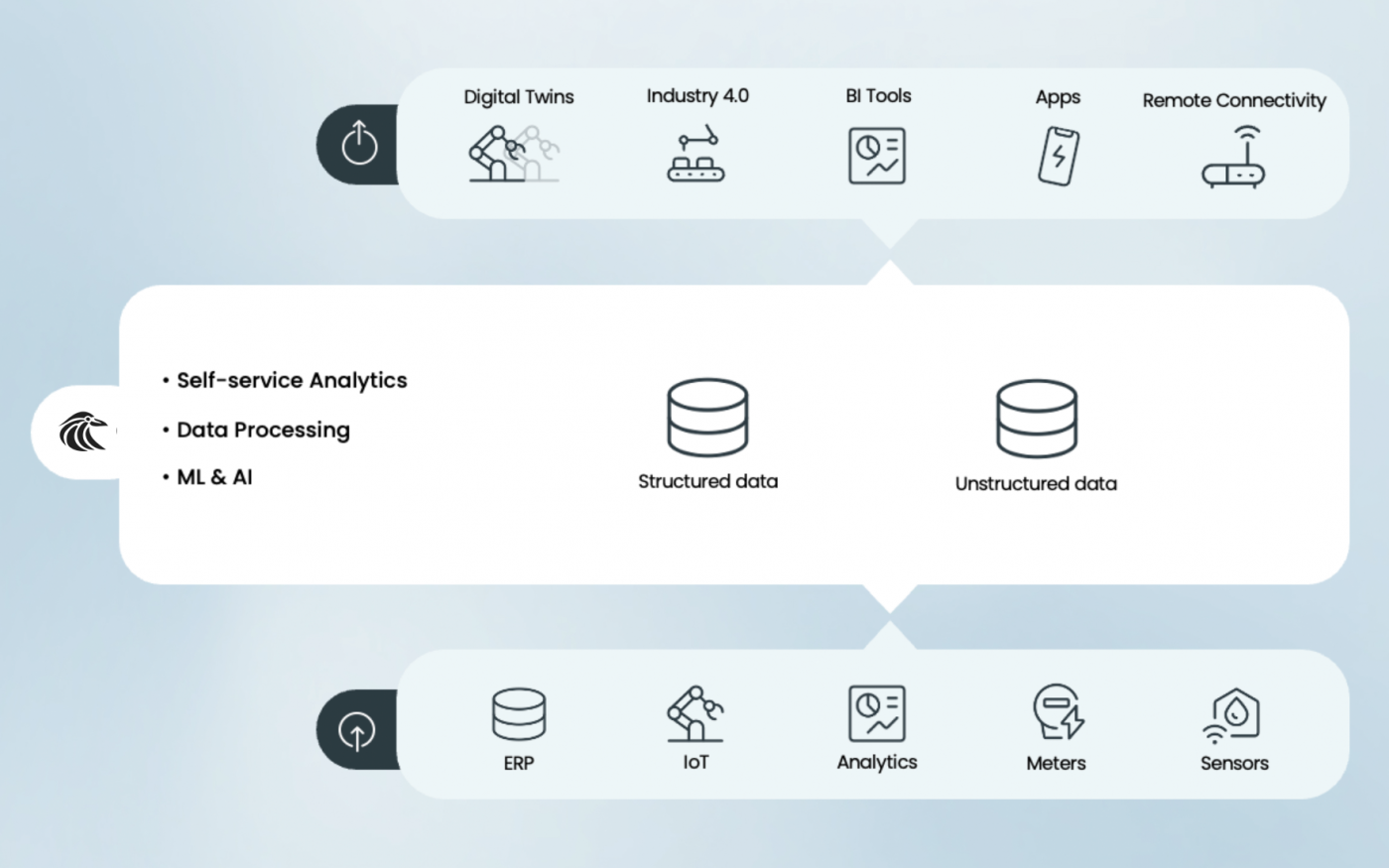
Corax data is based on four steps in working with your data. Ingest, Processing, Storage, and Consumption. The architecture is based on streaming technology allowing the overview of your business, customers or systems to always up to date. No nightly batch jobs to your data warehouse. In the ingest step, we have connectors to most formats and a framework for you to add your own ingest job. The streaming part allows you to correlate, calculate or accumulate your data efficiently. Storage can be multiple SQL/NoSQL/File datastores, and the consumption is made accessible via the query engine that abstracts the storage structure. Consumption can also be made directly from a Kafka Topic in the processing step.
WORK
Contact

Solution Architect

CCO

Solution Architect
If you prefer, you can also contact us on info@trifork.com
Subscribe
Find out the latest news first

