Introducing OwlSight, a configurable data monitoring platform. We have spent the past couple of months developing a new data quality monitoring platform to solve common problems we see when working with our clients.
Why Does Data Quality Matter?
But firstly, why data quality? At OpenCredo, we work on many data projects – from data warehouses, to data mesh implementations to AI – and they all rely on having data that you can trust. Poor data can lead to expensive mistakes, reputational damage and poor decision making long term.
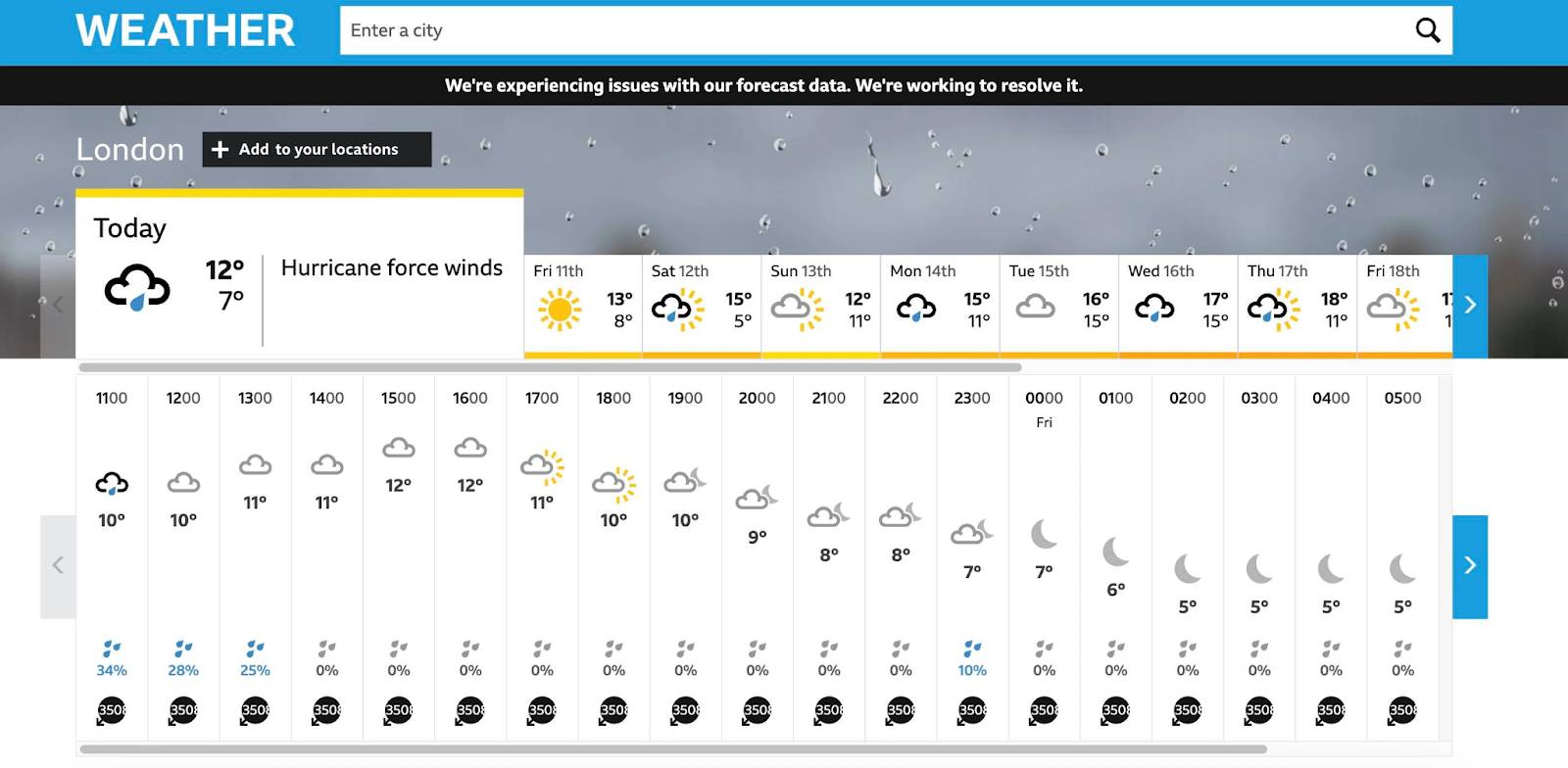
Just look at a recent BBC Weather report with hurricane force winds in London and 378C temperatures in Sydney. It was certainly embarrassing for the BBC with stories in the Daily Mail, the Express and the Guardian, among others. I’m sure the BBC have some pointed questions for their weather data supplier about their data quality process.
Why Choose OwlSight – A Flexible Data Quality Monitoring Platform?
We speak to a lot of teams who say that data quality monitoring involves time consuming manual work, either writing checks themselves (e.g. with great expectations) or having to specify each little rule for each data field with an off the shelf product. They have to spend a lot of time setting up and maintaining monitoring which could be used to do more useful, impactful work.
So we thought: can’t we get the computer to do the hard work for us? Let the computer adapt and check semantically if the values are within expected bounds, and expose unknown-unknowns without having to manually decide all the bounds beforehand.
OwlSight Features
So we created OwlSight. Our goal is to create a self-contained, optional add-on for our Platform Engineering Accelerator that monitors the data flowing through an ETL/ELT pipeline.
The data pipeline feeds data into OwlSight as it is processed, and OwlSight’s configuration dictates which fields it monitors and what to do if a data breach occurs.
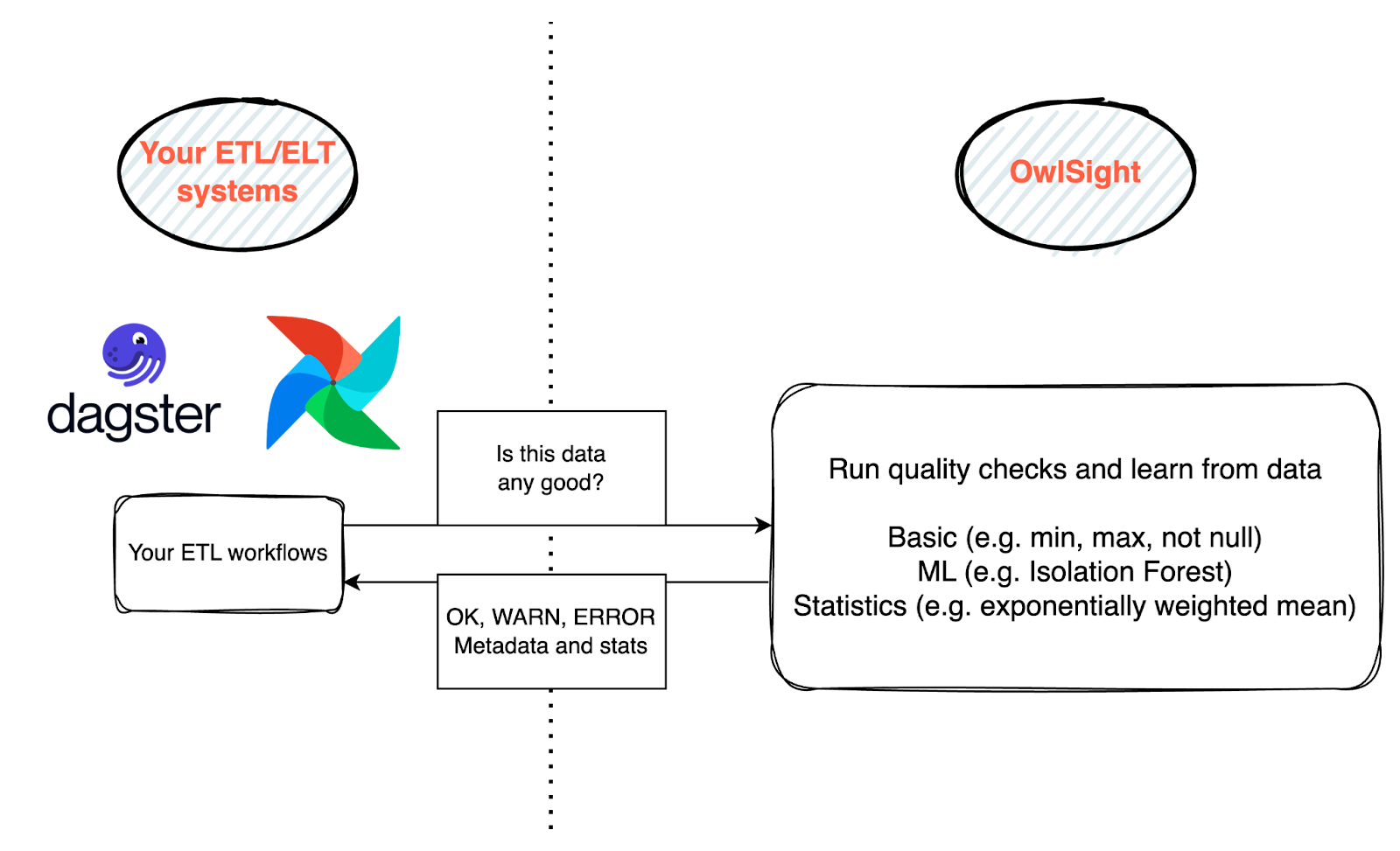
The key features are:
- Automated Anomaly Detection
- Comprehensive Metrics
- Inspection of Failed Records
- Data Exception Events
- Integration Flexibility
Automated Anomaly Detection for Improved Data Quality
OwlSight can detect anomalies in your data in two ways:
- In learning mode, OwlSight can collect statistics and training data to produce either statistical models (e.g. standard deviations from the mean) or ML models (e.g. an isolation forest). These known-good models can then be used for
- Using known-good datasets to train . This is useful when you know the shape of your data shouldn’t change much.
- Online detection where anomalies are detected against metrics from recent data (e.g. exponentially weighted mean or a continually trained isolation forest). This approach is resilient to seasonality and drift when you know your data can and will change.
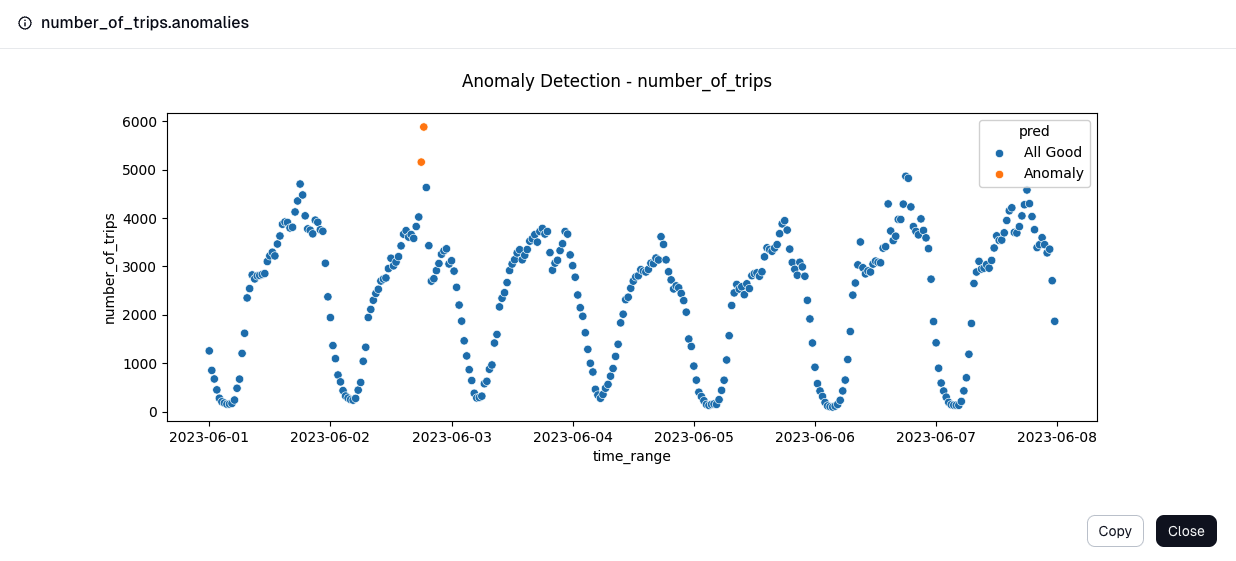
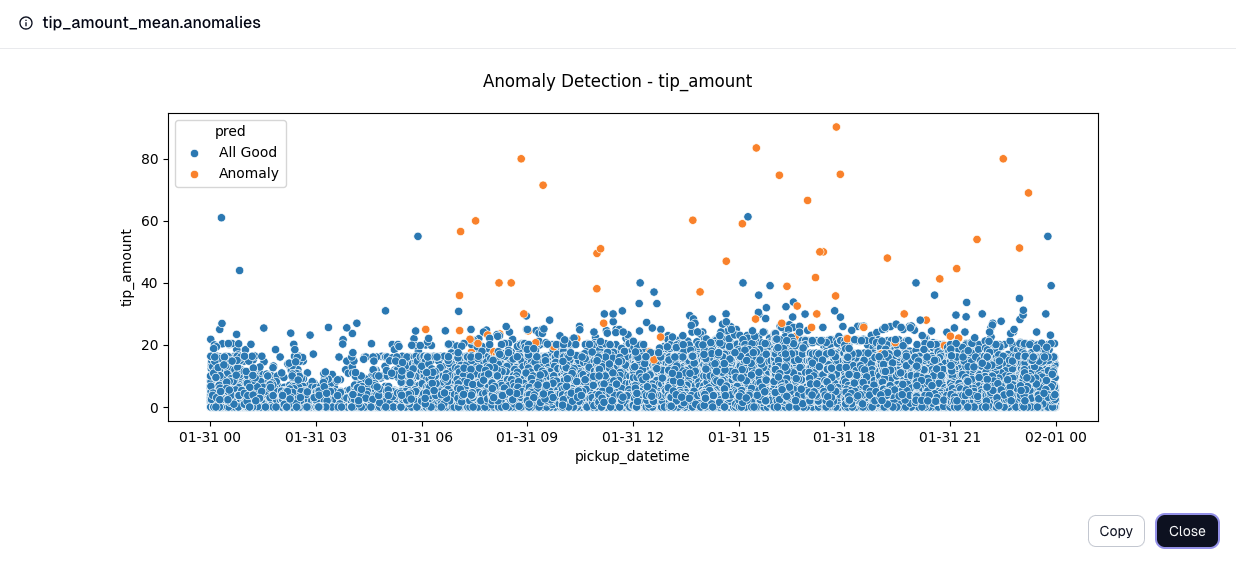
Comprehensive Metrics for Enhanced Data Insights
OwlSight keeps various statistics about the data flowing through it, regardless of the anomaly detection method used.
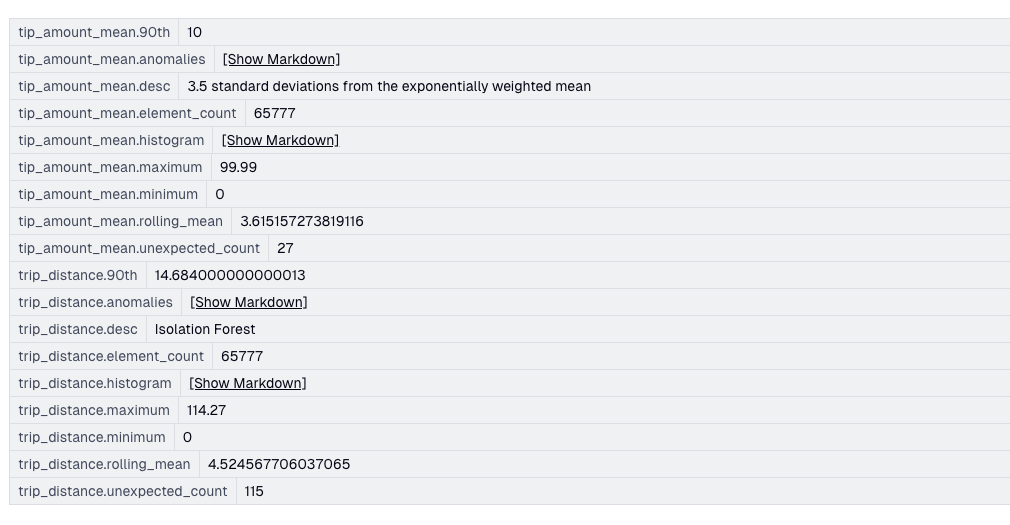
Inspection of Failed Records & Data Exception Events
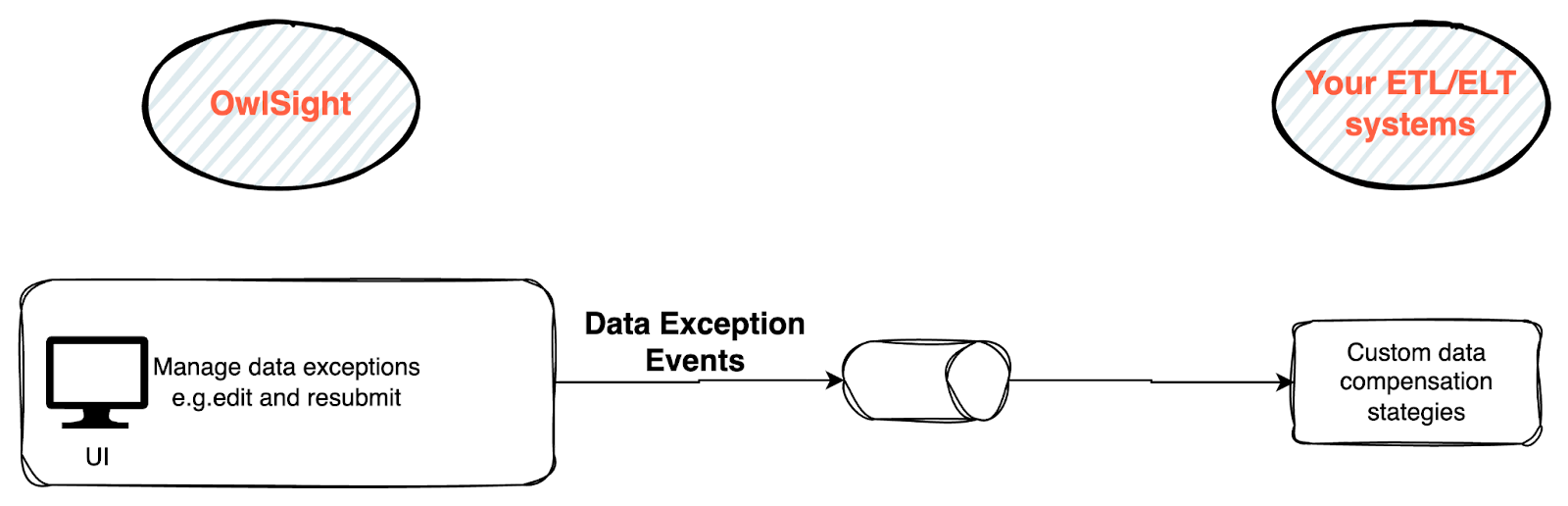
Failed checks are entered into a queue for exception processing, where a UI can be used to inspect the failed records and explain what rules it broke. What was the value, how far was it from the mean? Should it actually be a failure?
The user can then use the UI to update the rules accordingly, and potentially send the record back to the source ETL system as a data exception event where custom compensation logic can be used to, for example, correct the original data. Whatever is decided with a failed record, the decision is recorded in an audit log.
Integration Flexibility
OwlSight is implemented as a Python API right now, with plans for a more language-agnostic API in the future. It is not opinionated about what ETL, ELT or orchestration technology you are using.
It’s also not opinionated about where it sits in your data pipelines. This flexibility allows you to check data quality at different points in its lifecycle – some checks are best done at ingestion or cleaning, other business-focused checks are more appropriate later in the pipeline when preparing business-level “gold” data or doing feature engineering for AI/ML.
The Future
Though it’s still early days (we only finalised the name recently!), we’re excited about the upcoming developments for OwlSight, with several already in the works, including:
- Fully featured UIs for data exceptions, rules and results.
- Integrations with various data technologies like Spark and Flink.
- More metrics and statistical checks (e.g. zscore).
One interesting possibility with integrating anomaly detection at multiple points in a pipeline is responding to them differently depending on the context. For example, you may choose to exclude or edit an incorrect value during cleaning. But if you also have anomaly detection at later business-focused stages you may find interesting opportunities, like a customer with unusually high activity who can be targeted for personalised account management.
We’d Love to hear your thoughts!
Help us make our data quality platform even better by sharing some feedback in this quick questionnaire here.
Interested?
Would you like to hear more about OwlSight and our data work? Book in a chat here!
Related articles